Context Graphs - Hype vs Reality
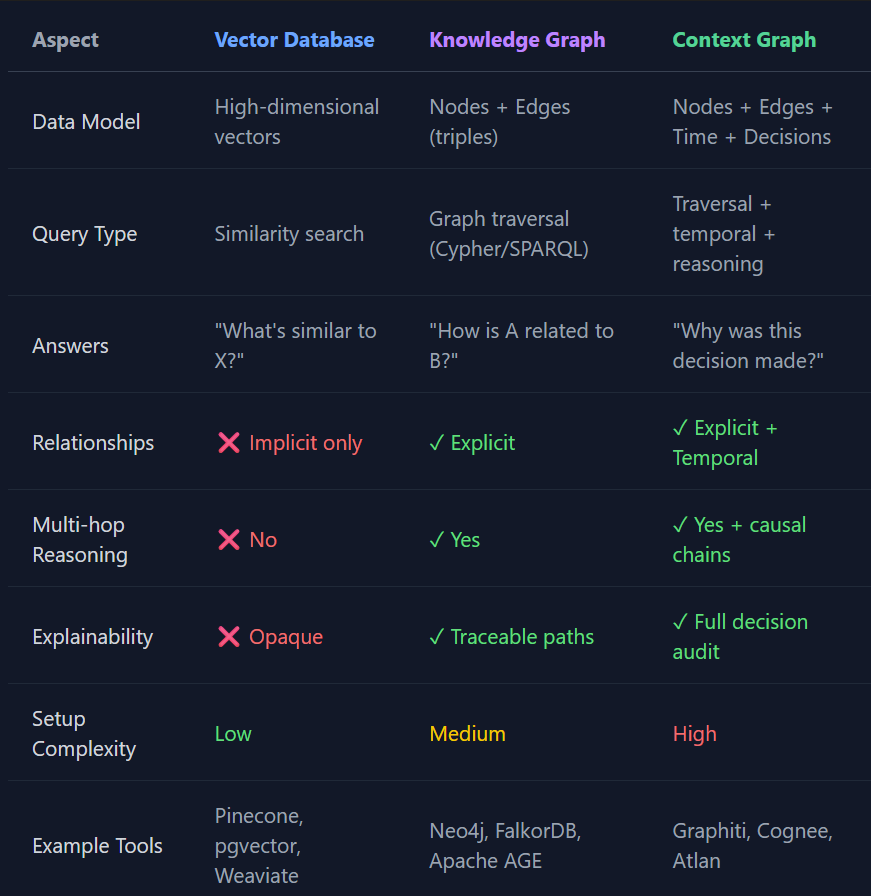
There’s quite a lot of hype recently about context graphs. What are they? How do they differ from a knowledge graph or vector database - concepts well known for a decade+. As usual nowadays the best answer to any question about existing knowledge is an LLM, so here’s a good comparison:
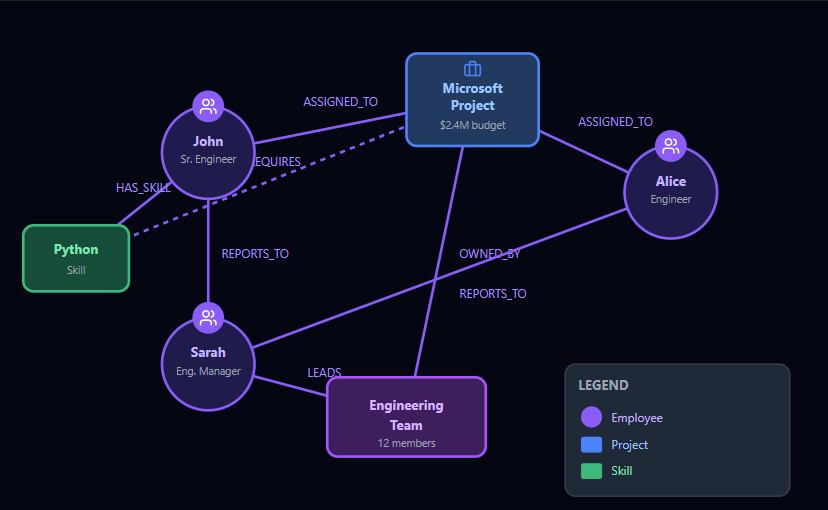
An example in a professional services organization for a knowledge graph could be something like this:
Then when we add some more contextual information to the graph we can get to what is the end-goal of building AI systems, what I call “INFORMED decision making”:
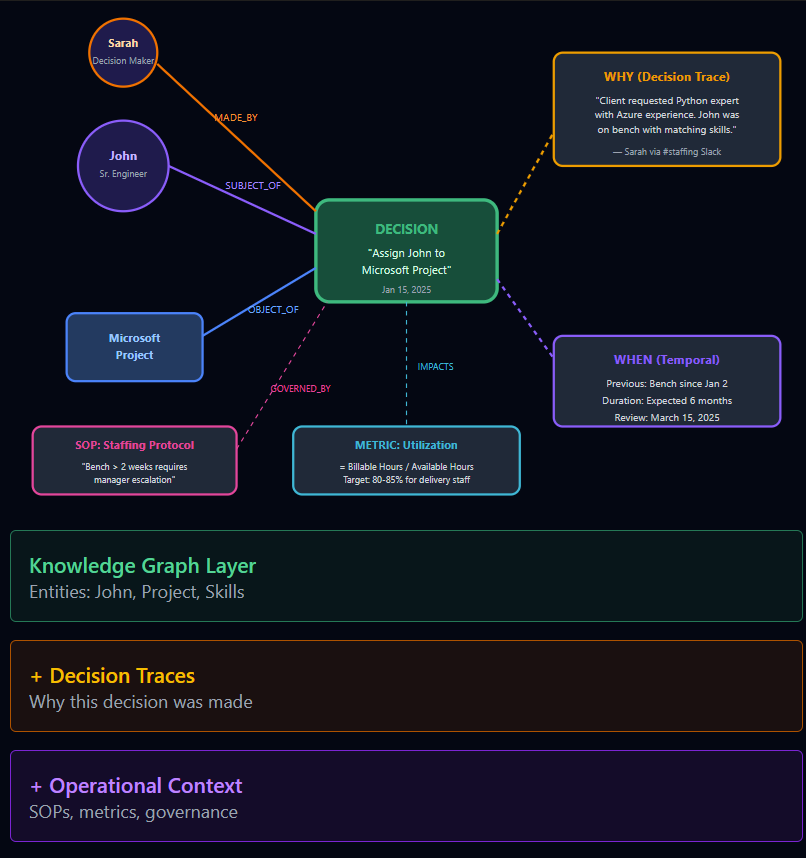
The additional value of that contextual information is being able to answer harder questions then a knowledge graph or a relational database can answer - it can answer why certain things happen or provide key information to decision making. E.g.: Query: “Should we give Acme Corp a 20% discount on renewal?”
Context Graph Response:
-
- Last year, VP approved 15% for similar-sized accounts (decision trace)
-
- Acme’s health score is 72 (analytical context: how we calculate health)
-
- Exception policy requires Director approval above 15% (SOP)
-
- Sarah approved a 20% exception for Beta Corp in Q3 (precedent)
Query: “Why is John’s utilization low this month?” Context Graph Response:
-
- Microsoft Project delayed by client (decision trace from #staffing)
-
- John was on approved training Jan 10-15 (temporal context)
-
- Utilization = Billable Hours / Available Hours (metric definition
-
- Training time excluded per policy (SOP reference)
The hard part comes with building structured context from unstructured data. However LLMs can greatly assist in this by looking for specific phrases in unstructured discussions or documents.
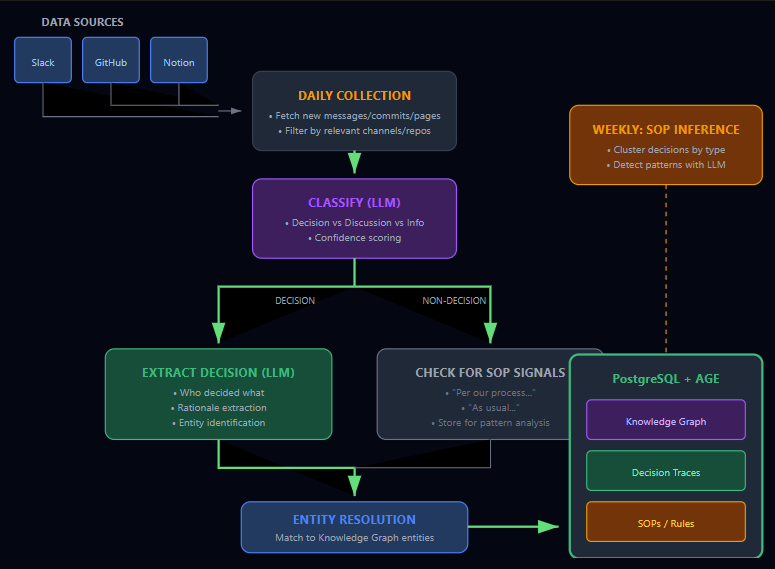
At the moment I am yet to see a production-grade deployment of a continuously updated context graph for a small even company. At this point in time there is still a need for a human in the loop to validate and update data suggested by an LLM based on the number of false positives and negatives we’ve observed in our work.